文章目录[隐藏]
一、背景
基本配置
5 台配置为 24C/125G/17T 的主机,每台主机上搭建了一个 elasticsearch 节点。采用的 elasticsearch 集群版本为 7.1.1。使用的管理工具包括 kibana 和 cerebro。
数据来源
数据来源为 kafka 的三个 topic,主要用于实时日志数据的存储和检索,由于实时性要求,所以需要将数据快速的写入到 es 中。

这里就分别称它们为 TopicA、TopicB、TopicC 吧。由于是调优写入,所以对源数据的一些基本的指标需要作出一个详细的梳理,便于后续分析。以下为三个 topic 的数据产生情况:

问题重现
在未做任何配置的情况下,分别使用 java 和 logstash 进行数据抽取,发现效率都不高,具体问题表现在:
1、kafka 数据积压严重,消费跟不上生产的速度。
2、elasticsearch 集群负载很高,大量写入被拒绝。
3、java 程序频繁抛出 RejectionException 异常。
4、主机 cpu 异常的高。
操作系统层面及 JVM 的配置调整这里不再阐述,有很多关于此类的文章可以参考。
我们分模块对各个部分进行调整,具体细节如下。
二、写入程序优化
从定数到定量
在使用的 java 程序中,我们将固定条数插入改为固定大小插入,由于使用的 es 版本较高,直接替换成了官方推荐的 BulkProcessor 方式。具体指定属性有:
#每 2w 条执行一次 bulk 插入
bulkActions: 20000
#数据量达到 15M 后执行 bulk 插入
bulkSizeMb: 15
#无论数据量多少,间隔 20s 执行一次 bulk
flushInterval: 20
#允许并发的 bulk 请求数
concurrentRequests: 10
这里的具体配置值,可以根据观察集群状态,来逐步增加。对于高版本的 es,可以通过 x-pack 的监控页面观察索引速度进行相应调整,如果 es 版本较低,可以使用推荐的 rest api 进行逻辑封装。在低版本的 es 中,统计写入速度的思路是:写一个程序定时检查索引的数据量,来计算。如果使用 python,就两行代码就能获取索引的数据总量。
call_list =es.indices.stats(index=index) total= call_list['indices'][index]['total']['indexing']['index_total']
也可以隔几分钟用 CURL 来粗略统计单个索引的数据量大小。命令如下:
#查询索引文档总量 curl -XGET -uname:pwd 'http://esip:port/_cat/count/index-name?v&format=json&pretty'
启动多个进程
由于 Bulkprocess 是线程安全的,所以我们可以使用多线程的方式来共享一个批处理器。更好的消费方式是,启动多个消费程序进程,将其部署在不同的主机上,让多个进程中开启的多线程总数和 topic 的分区数相等,并且将他们设置为同一个消费组。
每一个进程包含一个 bulkprocess 处理器, 可以提高消费和批量写入能力。同时避免了程序的单点问题,假如一个消费者进程挂掉,则 kafka 集群会重新平衡分区的消费者。少了消费者只是会影响消费速度,并不影响数据的处理。
“压测”,提升批量插入条数
通过对各个监控指标的观察,来判断是否能继续提高写入条数或增加线程数,从而达到最大吞吐量。
一、观察集群负载 Load Average 值
负载值,一定程度上代表了 CPU 的繁忙程度,那我们如何来解读 elasticsearch 监控页面的的负载值呢?如下是一个三个节点的集群,从左侧 cerebo 监控提供的界面来看,load 值标红,表明 es 的负载可能有点高了,那么这个具体达到什么值会显示红色呢,让我们一起来研究研究。
先从主机层面说起,linux 下提供了一个 uptime 命令来观察主机的负载。
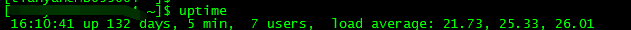
其中 load average 的三个值,分别代表主机在 1 分钟、5 分钟、15 分钟内的一个负载情况。有人可能会疑惑,26.01 是代表主机的负载在 26% 的意思吗,从我们跑的 es 集群情况来看,这显然不是负载很低的表现。
其实,在单个 cpu 的情况下,这个值是可以看做一个百分比的,比如负载为 0.05,表明目前系统的负荷为 5%。但我们的服务器一般都是多个处理器,每个处理器内部会包含多个 cpu 核心,所以这里负载显示的值,是和 cpu 的核心数有关的,如果非要用百分比来表示系统负荷的话,可以用具体的负载值 除以 服务器的总核心数,观察是否大于 1。总核心数查看的命令为:
cat/proc/cpuinfo |grep -c 'model name'
这台主机显示为 24,从 26 的负载来看,目前处理的任务需要排队了,这就是为什么负载标红的原因。
同时,这里列举一下,如何查看 CPU 情况
总逻辑 CPU 数 = 物理 CPU 个数 X 每颗物理 CPU 的核数 X 超线程数
# 物理 CPU 个数‘
cat /proc/cpuinfo| grep "physical id"| sort| uniq| wc -l
(我们的服务器是 2 个)
# 查看每个物理 CPU 中 core 的个数 (就是核数)
cat /proc/cpuinfo| grep "cpu cores"| uniq
(6 核)
# 查看逻辑 CPU 的个数
cat /proc/cpuinfo| grep "processor"| wc -l
(显示 24,不等于上面的 cpu 个数 * 每个 cpu 的核数,说明是开启了超线程)
二、观察集群在“忙什么”
通过 tasks api 可以直观的观察到集群在忙什么?,结果会显示包括父级任务,任务的持续时间等指标。命令如下:
curl -u username:pwd ip:port/_cat/tasks/?v | more

上面是我把副本设置为 0 后截的图。理论上还应该有一个 bulk[s][r] 操作。可以看到目前写入很耗时,正常情况一批 bulk 操作应该是毫秒级的,这也从侧面说明了 es 的负载很高。
从 task_id、parent_task_id 可以看出,一个 bulk 操作下面分为写主分片的动作 和写副本的动作。其中:
indices:data/write/bulk[s][p]:s 表示分片,p 表示主分片。
indices:data/write/bulk[s][r]:s 表示分片,r 表示副本。
三、观察线程池状态
避免大量写入被拒绝,可以通过观察 elasticsearch 后台日志或是通过使用 Thread pool Api 来观察内部线程池的使用情况,以及相应使用的队列大小,判断是否还可以继续调整写入配置参数。
curl -uusername:pwd-XGET "http://esip:port/_cat/thread_pool?v" | grep write
写入负载高的情况下,可能会出现大量拒绝,如下:
简易的写入流程
如下是 bulk 请求的简易写入流程,我们知道客户端会选择一个节点发送请求,这个节点被之称为协调节点,也叫客户端节点,但是在执行之前,如果定义了预处理的 pipline 操作(比如写入前将 key 值转换,或者增加时间戳等),则此写操作会被拦截并进行对应逻辑处理。从图中可以看出,写入操作会现根据路由出来的规则,决定发送数据到那个分片上去,默认情况下,是通过数据的文档 id 来进行路由的,这能保证数据平均分配到各个节点上去,也可以自定义路由规则,具体定义方式我们在下面会讲到。
接着,请求发送到了主分片上,主分片执行成功后,会将请求再转发给相应的副本分片,在副本分片上执行成功后,这个请求才算是执行完毕,然后将执行结果返回给客户端。可以看出多副本在写多读少的场景下,十分的消耗性能,近似的,多了几个副本就相当于重复写了几份数据。如果不考虑数据容灾,则可以适当的降低副本数量,或者去掉副本,提高写入速度。在我们的集群里面并没有用到 ingest 角色类型的节点,这里提出来说也是为了便于大家更好理解各个节点的角色分工。

通过 ES 提供的 API 观察各个节点的热线程,api 结果会显示出占用 cpu 高的线程,这也是我们可以优化的地方。大量写入场景下,这里一般大多数会显示:Lucene
Merge Thread 或者 [write],查询命令为:
GET /_nodes/hot_threads
三、主机部分
每个目录挂载不同的磁盘
在 data 目录下,我们分出了 10 个子目录,分别挂载到不同的硬盘上去。这相当于做了 raid0。能大大的提高写入速度。
配置多个 path.data 路径
由于在前面我们将 10 个目录分别挂载到不同的硬盘上去,所以在 elasticsearch.yml 的 path.data 属性中,我们配置多个路径,让数据能高效的写入不同的目录(硬盘),需要注意的是,如果只有一个索引,它的分片在某个节点的存储目录是固定的。所以这个特性,也只有在存在多个索引的情况下,能发挥出它的作用。
一个主机启动两个节点
es 实例分配内存不会超过 32G, 对于主机数量固定的我们, 如果 125G 的机器只放一个 es 节点,实属有点浪费,所以考虑在主机上启动两个 es 节点实例。
配置上需要注意关注以下几点:
1、http 的端口、节点间通信的 trasport 端口设置。
2、节点的角色分配。
3、脑裂配置对应修改。
4、path.data 属性修改(重要)
5、path.logs 属性修改。
均分硬盘
这里着重说一下第 4 点,同一个主机启动两个实例后,我们将 path.data 配置从原来的 10 个目录改为了各自配置 5 个不同目录。
path.data: /data01/esdata,/data02/esdata,/data03/esdata,/data04/esdata,/data05/esdata
一方面是 能够控制分片的分配,避免太多分片分配到一台主机上的其中一个节点上。另一方面是避免两个 es 进程对同一磁盘进行写入。随机写造成的磁头非常频繁的大面积移动肯定比单进程的顺序写入慢,这也是我们提高写入速度的初衷。
更换 ssd
ssd 能成倍的提高写入速度,如果使用 ssd,可能就不会折腾这篇文章出来了(偷笑)。
四、elasticsearch 部分
节点角色的设置

elasticsearch 提供几种类型的节点角色设置,需要在 elasticsearch.yml 配置中指定。
指定索引模板
可以根据需要修改,具体配置含义不再细说。
{
"order": 0,
"index_patterns": [
"topicA*"
],
"settings": {
"index": {
"refresh_interval": "40s",
"number_of_shards": "30",
"translog": {
"flush_threshold_size": "1024mb",
"sync_interval": "120s",
"durability": "async"
},
"number_of_replicas": "0",
"merge": {
"scheduler": {
"max_thread_count": "1"
}
}
}
},
"mappings": {
},
"aliases": {}
}
计算分片数
需要注意分片数量最好设置为节点数的整数倍,保证每一个主机的负载是差不多一样的,特别的,如果是一个主机部署多个实例的情况,更要注意这一点,否则可能遇到其他主机负载正常,就某个主机负载特别高的情况。
一般我们根据每天的数据量来计算分片,保持每个分片的大小在 50G 以下比较合理。如果还不能满足要求,那么可能需要在索引层面通过拆分更多的索引或者通过别名 + 按小时 创建索引的方式来实现了。
控制分片均分各个主机
以 TopicA 数据的一个索引为例,共 30 个分片,在 10 个节点上分配,应该每个节点分配 3 个分片,一个主机上一共有 6 个分片才算是均衡。如果分配不是这样,可以使用 cerebo 或者通过命令行进行分片迁移。
curl -X POST "localhost:9200/_cluster/reroute?pretty" -H 'Content-Type: application/json' -d'
{
"commands" : [
{
"move" : {
"index" : "test", "shard" : 0,
"from_node" : "node1", "to_node" : "node2"
}
}
]
}
配置索引缓冲区
即是指定 indices.memory.index_buffer_size 的大小,这个是一个静态变量,需要修改配置文件,重启后才能生效。
参考的计算公式:indices.memory.index_buffer_size / shards_count > 512MB(超过这个值索引性能并不会有太明显提高)
shards_count 为一个节点上面的分片数量,可以配置具体指或者一个占用 Es 内存总值的百分比。这里我们修改成了 20%(默认 10%)。
路由分片
可以使用 elasticsearch 提供的 routing 特性,将数据按一定规则计算后 (内部采用 hash 算法,把相同 hash 值的文档放入同一个分片中),默认情况下是使用 DocId 来计算,写入到分片,查询时指定 routing 查询,则可以提高查询速度,避免了扫描过多的分片带来的性能开销。
第一步:在创建索引模板的时候,需要在 mappings 中增加配置, 要求匹配到此索引模板的索引,必须配置 routing:
"_routing": {
"required": true
}
第二步: 为 BulkPorcess 创建 IndexRequest 时,通过 routing(java.lang.String routing) 方法指定参与计算 hash 的值。
注意这里是具体的值,而不是字段名称。
五、效果
经过如上的调优配置,三个 Topic 数据都能正常写入,集群文档总数在 170 亿,33 个索引,每个索引保留 4 天,242 个分片,集群负载正常。

六、踩过的坑
节点角色的设置方面
如果集群中节点数量不多,并且不需要对数据进行预处理,那么其实可以放弃使用 Ingest 类型的节点。默认情况下所有的节点的默认设置都为 true。所以我们手动将主节点和数据节点做如下设置
node.ingest: false
但是需要注意一点,x-pack 监控用到了这种类型的节点。会如下错误:
failed to flush export bulks 、no ingest node
解决办法是,打开这个属性配置,或者 elasticsearch.yml 中指定:
xpack.monitoring.exporters.my_local: type:
xpack.monitoring.exporters.local use_ingest: false
elasticsearch 线程池相关配置参数改变
从 5.0 版本以后,禁止了修改各个模块线程池的类型,线程池相关配置的前缀从 threadpool 变成了 thread_pool。 并且线程池相关配置级别上升至节点级配置,禁止通过使用 API 修改,因为场景是写多读少,所以我们只是增加了写队列的大小,配置为: thread_pool.write.queue_size: 1000。只能通过修改配置文件的方式修改。
单台主机负载过高
同一个主机两个节点都是数据节点,并且分片分配不均匀,导致这个主机 CPU 使用率在 98% 左右,后面通过迁移分片的方式将负载降低。
自定义 routing 写热点问题
比如按省份分的数据, 省份为北京的数据过多,西藏的数据很少,可能会带来写热点问题。所以合理的路由分配同样很重要。
作者:
侠梦,通信公司 java 研发工程师,关注 java、微服务架构、mysql、elasticsearch 等领域。
本文地址: https://www.xiongge.club/biancheng/elk-biancheng/1429.html
转载请注明:熊哥club → 提升 elasticsearch 写入速度的案例分享
©熊哥club,本站推荐使用的主机:阿里云,CDN建议使用七牛云。

关注微信公众号『熊哥club』
免费提供IT技术指导交流
关注博主不迷路~






